第1章 機械学習入門
第一章は導入部ですが、第5節で以下の“Mandatory”のパッケージが使われています。また、本ページでは“Optionnal”のパッケージを利用しています。
| Package | Descriptions | |
|---|---|---|
| RWeka | Mandatory | R/Weka Interface |
| DiagrammeR | Optional | Graph/Network Visualization |
機械学習の定義については「1.3 機械が学習する仕組み」に出てくるのでここでは割愛しますが、テキストでの機械学習はいわゆるバズワードである人工知能(AI)とは異なっています。
\[機械学習 \neq 人工知能(AI)\]
機械学習はガートナーのハイプサイクルにおいて2017年版(下図)でピークに位置し、

ハイプ・サイクル 2017年, ZDNetより引用
2018年版(下図)では他のテクノロジーとともに人工知能(AI)として幻滅期に位置しています。
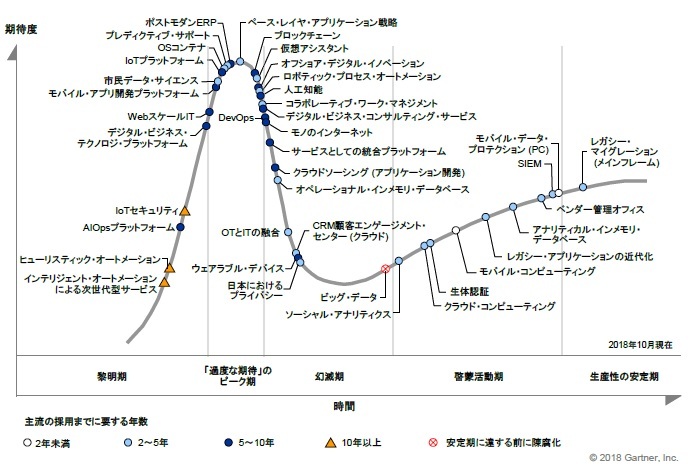
ハイプ・サイクル 2018年, ZDNetより引用
つまり機械学習(バズワードとしての人工知能)はクラウド技術のように利用して当たり前の局面になってきていると言えます。
1.1 機械学習の起源
膨大な記録がデータとして手軽にアクセスできるようになり、それらを手軽に処理できるコンピューティングパワーを手に入れたからこそ膨大なデータから意味を見出すための機械学習が発生し発展してきたと言えます。
1.2 機械学習の利用と失敗
機械学習が成功している分野
機械学習は主に大量のデータから特徴を抽出することを求められる分野で成果を上げています。例えば
- スパムメールフィルタ
- クレジットカード利用パターンの判断
- 様々な予測
大雑把にいえば、パターン認識(識別、推定、類推)が得意といえます。
機械学習の限界
機械学習は基本的に学習に利用したデータを元に計算を行いますので、学習に利用したデータから大きく外れるような推定(類推)はできません。ここが機械学習の限界です。
Newton MessagePad
Newtonは手書き文字認識機能を持ったPDA(Personal Digital Assistant)と呼ばれるスマフォの先駆けのような画期的な端末でした。音声通話機能はなかったと記憶してますが、データの通信機能を備えてはず。そこからエージェントサービスのような概念も生まれていたと記憶しています。

original MessagePad, The Registerより引用
機械学習の倫理
機械学習にかかわらずテクノロジーを利用する際には法的な規制だけでなく文化的な背景を考えた倫理を持って利用することが必要です。
1.3 機械が学習する仕組み
テキストで引用されている Tom M. Mitchell の定義
機械が自分の経験を利用して、将来同じような経験をしたときに性能を改善できるとき、 機械は学習している。 - ブレット・ランツ. Rによる機械学習 (Kindle の位置No.366-367). 翔泳社. Kindle 版.
は分かりにくいのでググってみると 『Machine Learning』(Tom M. Mitchell, 1997) という書籍で以下のように定義されているようです。
コンピュータプログラムがタスクTと評価尺度Pにおいて経験Eから学習するとは、タスクTにおけるその性能を評価尺度Pによって評価した際に経験Eによってそれが改善されている場合である
こちらの方が一見ややこしそうですが、言い換えると以下のようになり、より端的に表現していると思います。
データ(経験E)を用いて学習(タスクT)させることによりプログラムによる処理の評価(評価尺度P)が改善されるもの
つまり、機械学習は 『Machine Learning』(Tom M. Mitchell, 1997) での定義では、「データ(経験E)」、「学習(タスクT)」、「評価(評価尺度P)」を用いて表現すると以下のような構造のプロセスになると考えられます。
ところが、これでは書籍にある「抽象化」と「汎化」が見えません。「抽象化」と「汎化」は「学習」プロセス内のサブプロセスと考えると下図のようになり、書籍の図と一致します。
なお、学習プロセスを「抽象化」と「汎化」に分ける理由は以降で整理します。
データストレージ
「経験E」はデータとして、データストレージに格納されるのが一般的です。
抽象化
「タスクT」は前述のよう前半部分を担う「抽象化」プロセスと後半部分を担う「汎化」プロセスに分類できます。その内、前半の「抽象化」プロセスはデータストレージに格納されたデータに意味を与える作業、すなわちモデル化(モデリング)を行います。モデル化とは個々の具体的なデータからパターンとしてのモデルを作ることです。
モデル
モデルとは統計モデルや分析モデルなどと呼ばれるような数式(例えば回帰式)やクラスター分析結果のような関係を表すもの(グループ化されたデータ)、条件式などで記述された規則などを意味します。
汎化
機械学習において最も重要と言えるのが学習の後半部分を担う「汎化」プロセスです。
評価
機械学習のみならずモデルの評価は重要で、「相関係数が0.9を越えて」というような場合はうのみにすべきではありません。では、機械学習における評価とはなんでしょうか?よく言われるのは過剰適合(過学習)になっていないことや汎化性能を確認することです。
交差検証
個々のモデルの汎化性能を評価するもので、様々な方法が提案されています。ただし、交差検証を行ったからといって汎化性能(後述)が確保できる訳ではありません。
正則化
過学習
「過学習(overfitting)」は「過剰適合(overfitting)」とも呼ばれます。
汎化性能
機械学習で得られたモデルを評価する際に「汎化性能(generalization)」という言葉が出てきます。これは汎化プロセスでのモデリング結果を評価するものです。
1.4 実際の機械学習
入力データのタイプ
本項で説明されている入力データとはtidy dataです。tidy dataは下記のような性質を持ったデータです。
1. Each variable forms a column.
2. Each observation forms a row.
3. Each type of observational unit forms a table.この性質は「Coddの第三正規形」ですが、統計の言語に合わせた制約1として
4. Each value is a cell.が加わったものがRにおけるtidy dataの性質といえます。日本語にする2と
1. 個々の変数が一つの列をなす
2. 個々の観測が一つの行をなす
3. 個々の観測の構成単位の累計が一つの表をなす
4. 個々の値が一つのセルをなすとなります。
すなわち、構造と意味が一致しているデータをtidy dataと呼びます。本項の説明とtidy dataの説明を簡単に整理すると下表のようになることが分かります。
| 名前 | 本項における定義 | tidy dataでの性質 | No |
|---|---|---|---|
| 観測単位 | 測定されるものを持つ最小の主体 | 観測の構成単位がなす表 | 3 |
| インスタンス | 性質が記録された観測単位の具体例 | 個々の観測(行方向) | 2 |
| フィーチャー | 記録されたインスタンスの性質、属性 | 個々の変数(列方向) | 1 |
また、本項で説明されている行列形式(matrix format)とは、Rにおけるデータフレーム(data frame)そのものになります。図のテーブルは第二章で出てくる中古車に関するデータで、6のフィーチャー(変数、変量)と150のインスタンス(レコード、観測値)があることが分かります。
尺度
フィーチャーの形式で説明されている変数は、いわゆる尺度の話です。尺度自体の説明は省略します。
| 本項での変数名 | 相当する尺度 | Rでの変数型 |
|---|---|---|
| カテゴリ変数、名義変数 | 名義尺度 | factor, logical, character |
| 順序変数 | 順序尺度 | order |
| 数値変数 | 間隔尺度 | numeric |
| 数値変数 | 比率尺度 | numeric |
機械学習アルゴリズムのタイプ
機械学習アルゴリズムは目的により分類(カテゴリ分け)が可能です。
入力データに対応するアルゴリズム
テキストの表1-1を目的(カテゴリ)に着目して整理すると下表のようになります。
| 目的(カテゴリ) | アルゴリズム ()内は章番号 | タイプ |
|---|---|---|
| 分類 | 最近傍法(3)、単純ベイズ(4)、決定木(5)、分類ルール学習器(5) | 教師あり |
| 予測 | 線形回帰(6)、回帰木(6)、モデル木(6) | 教師あり |
| 分類・予測 | ニューラルネットワーク(7)、サポートベクターマシン(7) | 教師あり |
| 分類・予測 | バンギング(11)、ブースティング(11)、ランダムフォレスト(11) | メタ |
| パターン検出 | 相関ルール(8) | 教師なし |
| クラスタリング | k平均(9) | 教師なし |
ソフトウェア品質関連では、バグ数やレビュー指摘数がどれぐらいになるかの予測や市場バグの出る可能性があるのか否かの分類といったカテゴリが関係してくると思われます。
1.5 Rを使った機械学習
機械学習はData Science Workflowにおける“Model”と“Infer”のプロセスに該当します。
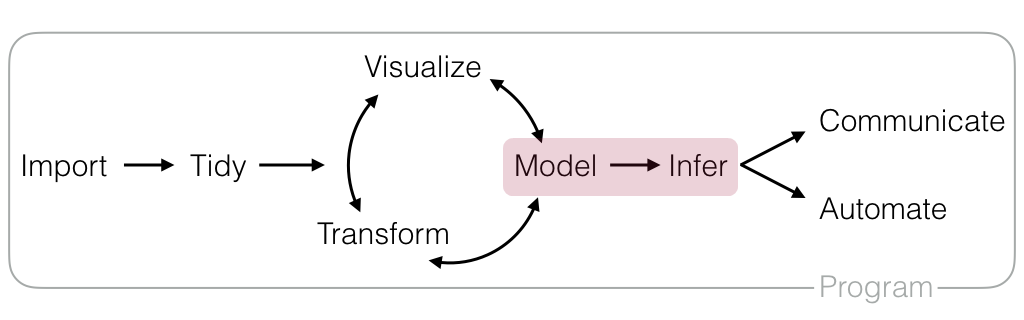
Fig. Data Science Workflow, CC BY 4.0 RStudio, Inc.
Rの 機械学習に関するタスクビュー を見ると分かりますが、既に16のサブカテゴリで100を超える機械学習関連パッケージが開発されています。機械学習というとデプロイ前提で使われるPythonという印象ですが、Rも負けていません。
Rパッケージのインストール
デフォルトのCRANミラーサイトを設定してない場合はパッケージをインストールする前に以下のコマンドで最もネットワーク的に近いと思われるCRANのミラーサイトを対話的に選択しておいてください。
ダウンロードするミラーサイトが決まったら以下のコマンドでパッケージをインストールします。
RWekaパッケージは5章ならびに6章で使用するRからJavaで書かれた Weka (Waikato Environment for Knowledge Analysis) という機械学習ソフトウェアにアクセスするために必要なパッケージです。RWekaパッケージはRWekajarsパッケージ、rJavaパッケージを通してJavaを利用しますが、rJavaパッケージがJavaを利用するためにインストール後に設定が必要です。
Javaのインストールと設定
最近のOSではJavaがプレインストールされていませんので、別途、Java(JDK, not JRE)をインストールしておく必要があります。 Oracle Java はライセンスが厄介なので勉強会での利用には OpenJDK をおすゝめします。
Ubuntuの場合には以下の2行のコマンドでインストールと設定か可能です。なお、OpenJDKのバージョンはLTSとなる8または11をおすゝめします。
Ubuntu 16.4LTSの場合
Ubuntu 18.4LTSの場合
Ubuntu 18.4LTSではデフォルトのJDKをインストールする方が簡単です。
OpenJDKを利用したい場合にはJDKのインストール後に必ず/usr/lib/R/etc/javaconfに記載されている環境変数JAVA_HOMEをOpenJDKへのパスに変更してからsudo R CMD javaconfを実行してください。
Java(JDK)をインストールしただけではRWekaパッケージは利用できません。必ず設定を行ってください。また、JREでは動きませんので必ずJDKをインストールしてください。
Rパッケージの読込みと開放
パッケージを読込む場合はlibrary関数、または、require関数を用いてください。
読込んだパッケージを開放する場合はdetach関数を利用しますが、パッケージ名の指定方法に注意してください。
1.6 まとめ
- 機械学習アルゴリズムはデータ(tidy data)をモデルにまとめる
- 機械学習アルゴリズムは目的に応じて適切なものを選択する
- モデルは予測または記述(説明)を目的として利用される
- 機械学習においてもデータハンドリングは重要
- 汎化性能の確認などの評価も重要
参考資料
機械学習
- 機械学習とは何か? – 機械学習の定義と使える言い回し
- いまさら聞けない機械学習のキホン
- 機械学習(Machine Learning)
- 「そのモデルの精度、高過ぎませんか?」過学習・汎化性能・交差検証のはなし
- RでL1 / L2正則化を実践する
Tidy Data
『R for Data Science』 の第12章ではtidyであることは以下と定義し下図を用いて説明しています。
There are three interrelated rules which make a dataset tidy:
* Each variable must have its own column.
* Each observation must have its own row.
* Each value must have its own cell.
Java関連
- JavaからRを動かすrJavaを動かしたい
- rjavaのインストールメモ&rincanterの設定(OSX,Ubuntu)
- Java R Interface (JRI) を用い 統計解析環境 R を Java から使用する
- ‘library()’ コマンドを使用して ‘rJava’ パッケージをロードしようとすると、エラーが発生します。
- パッケージをインストールするときに ’rJava’のloadNamespace()で.onLoadが失敗しました