第4章 確率的学習 - 単純ベイズを使った分類
第4章 確率的学習 - 単純ベイズを使った分類
第四章で学ぶ単純ベイズ(英語では“Naive Bayes Classifier”、ナイーブベイズ分類器ですので、ここではナイーブベイズと呼称します)は第三章で学んだ最近傍法と同じ分類を目的としたアルゴリズムです。第三章では数値データを用いた分類を行いましたが、第四章はテキストデータを用いた分類です。

scikit-learn algorithm cheat-sheet
ナイーブベイズは実例で出てくるスパムフィルタを始めとして比較的身近なところで使われています。有名な実例としては はてなブックマークでのカテゴリ分類 があげられます。実例から分かるようにナイーブベイズはテキストに含まれるトークン(単語)パターンを学習して振り分けるような処理に向いています。また、実装が比較的簡単で学習時間も短い割には性能が良いので様々な実サービスで使われているようです。ただし、テキストをトークン(単語)に分割する必要がありますので、第四章の実例の大半はテキストデータを扱うためのマイニング手法についての説明になっています。ちなみに、機械学習における分類器はナイーブベイズの他にランダムフォレストやサポートベクターマシンなどがあります。
なお、本ページで利用しているデータならびにコードの一部はテキスト付属のサンプルファイルをベースにしています。また、【】で表記されているページ数は書籍『Rによる機械学習(第2刷)』に基づいています。
R Packages
テキストで利用しているパッケージは“Mandatory”のパッケージのみですが、本ページでは“Optional”のパッケージも利用しています。
| Package | Descriptions | |
|---|---|---|
| e1071 | Mandatory | Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien |
| gmodels | Mandatory | Various R Programming Tools for Model Fitting |
| snowballC | Mandatory | Snowball Stemmers Based on the C ‘libstemmer’ UTF-8 Library |
| tm | Mandatory | Text Mining Package |
| wordcloud | Mandatory | Word Clouds |
| caret | Optional | Classification and Regression Training |
| doParallel | Optional | Foreach Parallel Adaptor for the ‘parallel’ Package |
| klaR | Optional | Classification and Visualization |
| skimr | Optional | Compact and Flexible Summaries of Data |
| tidyverse | Optional | Easily Install and Load the ‘Tidyverse’ |
| timelyportfolio/d3vennR | Optional | htmlwidget for interactive Venn/Euler diagrams in R [GitHub] |
4.1 単純ベイズ法とは何か 【P80】
ナイーブベイズはその名の通りベイズの定理(ベイズ推定)を基礎にしたアルゴリズムを用いた分類器です。 ベイズ推定とはベイズ確率の考え方に基づき観測された事象から推定したい事象を確率的な意味で推定する 方法です。つまり、ナイーブベイズ(分類器)はトレーニングデータを利用して個々の結果が起きる観測確率を計算し、テストデータに対して観測確率を用いて最も正しそうな分類(クラス)を決定します。考え方はシンプルですが様々な用途に使われていることからも比較的性能を確保できる(確保しやすい)アルゴリズムといえます。
ベイズ法の基本概念 【P80】
ベイズの定理(ベイズ法)における確率とは古典的統計学における頻度に基づく確率でなく、事象における直感的信頼度、すなわち、事前の事象の結果(確率)に基づいて決まる相対的なものであるとしている点です。例えばテキストにあるように「SMSを受信」しなければ「スパムを受け取る」こともないわけです。つまり、「SMSを受信(事前の確率)」して、初めて、受信した「SMSがスパムなのかハムなのか(事後確率)」が決まるということです。
確率とは何か 【P81】
本項における確率とは観測された事象の頻度に基づく確率のことです。事象\(A\)が発生する確率は\(P(A)\)と表すことができます。逆に事象\(A\)が発生しない確率は\(P(\lnot A)\)と表します。\(\lnot\)は「否定」を意味する論理記号です。
同時確率とは何か 【P82】
事象\(A\)と事象\(B\)の発生に関係性がなくお互いに独立である(独立事象である)場合、事象\(A\)と事象\(B\)が起こる確率を同時確率と呼び
\[P(A \cap B)\]
と表現します。このような事象の独立性は、事象\(A\)が発生しようとしまいと事象\(B\)の発生にはなんの影響もない、つまり、事象\(A\)の発生は事象\(B\)の確率に何の影響も与えないない(逆もしかり)ということを意味しています。例えば、コインとサイコロを同時に投げる場合は独立事象に相当します。
\[P(A \cap B) = P(A \land B) = P(A) \times P(B)\]
一方、事象\(A\)と事象\(B\)の発生に何等かの関係がある場合、例えば、福引の回転式抽選器のように一回目の出玉で二回目の出玉の確率が変わるような場合を従属事象(または排反事象)、起こる確率を条件付き確率と呼び、以下で表現します。
\[P(A \mid B)\]
この条件付き確率を上手く説明しているのが、ナイーブベイズの基礎となっているベイズの定理です。
【閑話】ソシャゲのガチャは独立事象?従属事象?
ガチャ確率計算機の作者が語る!「これが、ガチャの落とし穴だ!」
ベイズの定理による条件付き確率の計算 【P84】
ベイズの定理は以下で表現されます。
\[P(A \mid B) = \frac{P(A \cap B)}{P(B)}\]
左辺の\(P(A \mid B)\)は前述のように条件付き確率と呼ばれ事象\(B\)が起こった場合に事象\(A\)が起こる確率です。スパムフィルタで考えると
事象\(B\) : あるキーワードを含むSMSを受信する確率
事象\(A\) : それがスパムである確率
といえます。右辺は【P83 図4-3】のベン図の説明の通りで\(P(A \cap B)\)は同時確率と呼ばれ事象\(A\)と事象\(B\)が同時に起こる確率、\(P(B)\)は事象\(B\)が起こる確率です。つまり、スパムフィルタで考えると「あるキーワードを含むSMSを受信」しない限り「それがスパム」にはなりえないので、事象\(A\)と事象\(B\)はそれぞれ独立に起こる独立事象ではなく、事象\(B\)が起きた時に事象\(A\)が発生する従属事象といえます。
この式を変形させると
\[P(A \cap B) = P(A \mid B) \times P(B)\]
となり\(P(A \cap B)\)は
\[P(A \cap B) = P(B \cap A)\]
と入れ替えても等価なので、\(P(A \mid B)\)を以下のように変形することができます。
\[P(A \mid B) = \frac{P(A \cap B)}{P(B)} = \frac{P(B \cap A)}{P(B)}\] \[ = \frac{P(B \mid A)P(A)}{P(B)} \propto P(B \mid A)P(A)\]
事象\(A\)が発生する確率から見ると事象\(B\)が発生する確率は定数と見なせるので、省略して上記右辺のような形に変形できます。
条件付き確率と同時確率の関係性【テキスト外】
条件付き確率は前述の通り以下で表現することができます。
\[P(A \cap B) = P(A \mid B) \times P(B)\]
一方、事象\(A\)と事象\(B\)が独立であるならば、事象\(B\)が発生した場合、事象\(A\)が起こる確率は事象\(B\)の発生に影響されないため、事象\(A\)が発生する確率そのものであることから上記の式を利用すると以下のように表現することができます。
\[P(A) = P(A \mid B)\]
逆もしかりで、\(P(B) = P(B \mid A)\)となります。
【P85】
閑話休題、ベイズの定理を日本語で表すと以下になります。
\[事後確率 = \frac{尤度 \times 事前確率}{周辺尤度(エビデンス)} \propto 尤度 \times 事前確率\]
すなわち、あるキーワードを含むSMSがスパムである確率(事後確率)は、スパムがあるキーワードを含む確率(尤度)とスパムである確率(事前確率)から計算できることが分かります。
事象\(A\)と事象\(B\)を分かりやすく表現し\(A = spam\)、\(B = Msg\)とすると
\[P(spam \mid Msg) = \frac{P(spam \cap Msg)}{P(Msg)} \propto P(Msg \mid spam)P(spam)\]
となります。スパムがあるキーワードを含む確率(尤度)\(P(Msg \mid spam)\)は、過去のデータから頻度表を作成すれば求めることができます。例えば、あるキーワードが以下のような頻度でスパムに含まれていた場合
となり、合計は必ず\(1\)になります。スパムがあるキーワードを含む確率(尤度)\(P(Msg \mid spam)\)は、尤度表から\(\frac{4}{5} = 0.8 = 80\%\)で、スパムである確率\(P(spam)\)は頻度表または尤度表から\(\frac{5}{15 + 5} = 0.25 = 25\%\)だと分かりますので、あるキーワードを含むSMSがスパムである確率(事後確率)\(P(spam \mid Msg)\)は
\[P(spam \mid Msg) \propto P(Msg \mid spam)P(spam)\] \[= 0.8 \times 0.25 = 0.2 = 20\%\]
ということが分かります。
単純ベイズアルゴリズム 【P86】
単純ベイズを使った分類 【P87】
実際のメッセージ\(Msg\)は複数の単語\(W_i, i=1,...,n\)から構成されていますので語順を考慮しなければ(単語間の独立性を仮定すれば)前述のように論理積(\(\land\))を使って
\[P(spam \mid Msg) \propto P(W_1 \land ... \land W_n \mid spam)P(spam)\] \[ = P(spam) \prod_{i = 1}^{n}{P(W_i \mid spam)}\]
と表現できます。スパムのみならず文書は単語の出現にはなんらかの関係性があると考えるのが普通ですが、この関係性を無視して独立性を仮定して確率の積として単純化するのでナイーブベイズがナイーブ(単純)と言われる由縁です。
上記の式を一般化すると\(F_i, i = 1, ..., n\) のフィーチャー(スパムフィルタでは単語)がある場合、クラス\(C\)(目的変数)において\(C_L\)(スパムフィルタではスパムまたはハム)が発生する確率は\(F_1,...,F_n\)(説明変数)に依存する係数(定数)\(Z\)を用いて以下のように定義できます。
\[P(C_L \mid F_1, ..., F_n) = \frac{1}{Z}P(C_L)\prod_{i = 1}^{n}{P(F_i \mid C_L)}\]
これがナイーブベイズの計算式です。最も確率の高いクラスが該当するクラスと推定できます。
\[\hat{C_L} = \mathop{\arg \max} \limits_{C_L} P(C_L) \ \prod_{i=1}^n P(F_i \mid C_L)\]
ラプラス推定量 【P89】
テスト時にトレーニングデータに含まれていないフィーチャー(スパムフィルタでは単語)が出てきた場合、事前確率が\(P(C_L) = 0\)となるため、事後確率も\(P(C_L \mid F_1, ..., F_n) = 0\)となってしまいます。このような問題はゼロ頻度問題と呼ばれ、解決するため(確率を\(0\%\)にしないため)にフィーチャーの出現回数に小さな値(通常は0にならないように\(1\))を加える処理を行います。この処理をラプラススムージングと呼び、加える値をラプラス推定量と言います。
アンダーフロー対策【テキスト外】
実例を見るとわかりますがSMSメッセージには様々な単語が含まれていますので、単語数はかなりの数になります。\(\prod P(F_i \mid C_L)\)の計算において\(1\)以下の値の掛け算が多数回行われアンダーフローが起きる可能性があります。アンダーフローが起こると事後確率\(P(C_L \mid F_1,...,Fn)\)が常に\(0\%\)となってしまいますので、対数変換を行い乗算(\(\prod\))を加算(\(\sum\))に変えることでアンダーフローの発生を抑止します。なお、\(log(0)\)は計算できませんので、前述のラプラススムージングとの併用が必須となります。
単純ベイズにおける数値フィーチャー 【P90】
テキストでは数値フィーチャー(連続値)を扱うにはカテゴリカルデータ化する必要があると記載されています。また、本ページの頭に掲載している“scikit-learn algorithm cheat-sheet”でもナイーブベイズ分類器は「テキストデータ」の分類用とされています。
しかし、Rに実装されているナイーブベイズ分類器は連続値(数値)を直接引数に取ることができます。テキストで利用しているe1071::naiveBayes関数に限らずklaRパッケージのklaR::NaiveBayes関数も連続値を扱えます。連続値の場合は、事前分布を元に事後分布を計算するので基本的な考え方は変わりません。詳しくは このあたり や このあたり 具体的な事例は このあたり を参考にしてみてください。
4.2 実例 - 単純ベイズ法によるSMSスパムのフィルタリング 【P92】
ナイーブベイズをスパムフィルタに適用するためには、前節で学んだように
- 尤度(スパムがあるキーワードを含む確率)
- 事前確率(スパムである確率)
- 周辺尤度(全てのSMSの中であるキーワードが含まれている確率)
を計算できるデータが必要になります。これらは全て頻度表から求めることができますので、スパムか否かのラベリングされたメッセージをターム(テキストでは単語)に分解し、それを元に頻度表(頻度表が作成できるデータ)を作成する必要があります。
手順の説明【テキスト外】
本節ではナイーブベイズを用いたスパム判定を行うための手順が記載されていますが記載が少し複雑なので必要な手順のみを下表にまとめました。ワードクラウドなんぞ飾りです。
| Step | Processing | Input Type | Output Type | Package |
|---|---|---|---|---|
| 1 | データの収集 | CSV | ||
| 2 | データの研究と準備 | |||
| -1 | データの読み込みと確認 | CSV | Data Frame | (Base R) |
| -2 | データ型の変換 | Data Frame | Data Frame | (Base R) |
| -3 | コーパス化 | Data Frame | List | tm |
| -4 | クレンジング(小文字化) | List | List | tm |
| -5 | クレンジング(数字の削除) | List | List | tm |
| -6 | クレンジング(Stopwordの削除) | List | List | tm |
| -7 | クレンジング(記号の削除) | List | List | tm |
| -8 | クレンジング(ステミング) | List | List | tm, SnowballC |
| -9 | クレンジング(空白の削除) | List | List | tm |
| -10 | 単語への分割(トークン化) | List | Matrix | tm |
| -11 | 訓練・テストデータへ分割 | Matrix | Matrix | (Base R) |
| -12 | ラベルデータの作成 | Data Frame | Vector | (Base R) |
| -13 | 頻出度の低いトークンの削除 | Matrix, Vector | Matrix | tm |
| -14 | カテゴリカルデータへ変換 | Matrix | Matrix | (Base R) |
| 3 | データによるモデルの訓練 | Matrix, Vector | List | e1071 |
| 4 | モデルの性能評価 | |||
| -1 | 判定(予測)の実行 | List, Matrix | Vector | (Base R) |
| -2 | 判定(予測)結果の評価 | Vector | List | gmodels |
手順の大半をクレンジング処理に費やしていることが分かります。また、それらの処理はtmパッケージ(Rにおけるテキストマイニング処理のデファクトスタンダードなパッケージ)で行われており、リスト型やマトリクス型を使っている点に留意してください。
ステップ1 - データの収集 【P92】
テキストに記載されているSMSスパムコレクションのリンク先は404なのですが、UC Irvine機械学習リポジトリの SMS Spam Collection Data Set がオリジナルデータです。
注意【テキスト外】
データファイルの一部にエンコードミスがあり Second Edtionにて修正 されたファイルが公開されていますが、1072行目の文末に「“」という文字が単独で存在しているために1073行目が正しく処理されません。本ページでは修正ファイルに更に修正を加えたファイルを使用していますのでテキストとは若干異なった処理結果になっています。また、Windows環境ではエンコードを指定しないで読み込むとエンコーディング処理の不具合でコーパス処理の際にエラーが出ますので、必ずエンコーディングを指定してください。
エンコード指定方法
ステップ2 - データの研究と準備 【P93】
ステップ2はナイーブベイズ(e1071::naiveBayes関数)で使えるようなデータを整形(データハンドリンク)するための前処理に関する説明です。データハンドリングはモデリングの前段階のステップです。
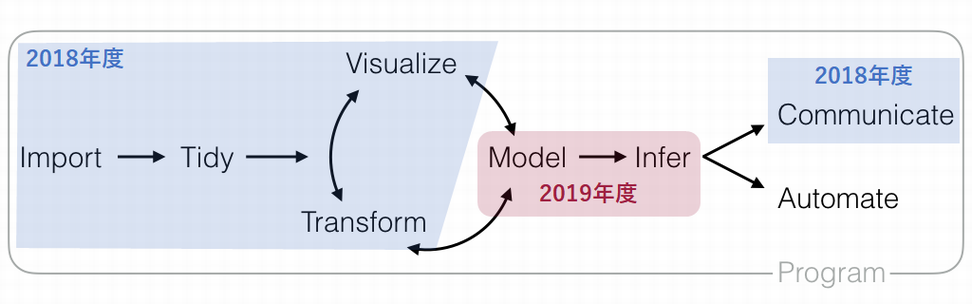
Data Science Workflow, RStudio
手始めに読込んだデータを確認してみます。文字数制限のあるSMSメッセージなので特徴的な単語(略語)が目につきます。また、スパムは大文字を使う傾向があるように見えます。
構造の確認 【P94】
str関数は名前の通り構造(structure)を表示する関数です。
## 'data.frame': 5559 obs. of 2 variables:
## $ type: chr "ham" "ham" "ham" "spam" ...
## $ text: chr "Hope you are having a good week. Just checking in" "K..give back my thanks." "Am also doing in cbe only. But have to pay." "complimentary 4 STAR Ibiza Holiday or £10,000 cash needs your URGENT collection. 09066364349 NOW from Landline"| __truncated__ ...
サマライズ系関数の例【テキスト外】
データフレームの内容を確認するにはskimrパッケージのようなサマライズ系のパッケージを使った方がわかりやすい表示をしてくれます。
閑話休題。ラベリングデータであるtypeを因数型変数に変換しておきます。因数型変数はインデックスのついたベクトル変数で、デフォルトでは水準名をアルファニューメリック順にソートしてインデックスを割り当てます。
## 'data.frame': 5559 obs. of 2 variables:
## $ type: Factor w/ 2 levels "ham","spam": 1 1 1 2 2 1 1 1 2 1 ...
## $ text: chr "Hope you are having a good week. Just checking in" "K..give back my thanks." "Am also doing in cbe only. But have to pay." "complimentary 4 STAR Ibiza Holiday or £10,000 cash needs your URGENT collection. 09066364349 NOW from Landline"| __truncated__ ...##
## ham spam
## 4812 747
データの準備 - テキストデータのクリーニングと標準化 【P94】
クレンジング処理はtmパッケージを利用しますので、最初にtmパッケージを読み込んでおきます。
コーパスへの変換【P95】
最初にデータフレームをコーパスに変換し、その実態を確認します。
## <<VCorpus>>
## Metadata: corpus specific: 0, document level (indexed): 0
## Content: documents: 5559
コーパスの実態を確認する【テキスト外】
<<VCorpus>>とは何かよくわからないのでクラスと構造を確認してみます。
## [1] "VCorpus" "Corpus"## List of 1
## $ 1:List of 2
## ..$ content: chr "Hope you are having a good week. Just checking in"
## ..$ meta :List of 7
## .. ..$ author : chr(0)
## .. ..$ datetimestamp: POSIXlt[1:1], format: "2019-08-24 06:52:42"
## .. ..$ description : chr(0)
## .. ..$ heading : chr(0)
## .. ..$ id : chr "1"
## .. ..$ language : chr "en"
## .. ..$ origin : chr(0)
## .. ..- attr(*, "class")= chr "TextDocumentMeta"
## ..- attr(*, "class")= chr [1:2] "PlainTextDocument" "TextDocument"
## - attr(*, "class")= chr [1:2] "VCorpus" "Corpus"リスト型のオブジェクトで様々な属性データを持てるようになっているのがわかります。一般的にコーパスとは研究や分析などのために体系的に収集した言語データに情報を付与したものを指します。なので、VCorpusオブジェクトは属性に著者などのデータを持たせることができますがテキストのような分析には過剰な仕様に思えます。
コーパスの中身を確認【P96】
tm::inspect関数を用いるとVCorpusオブジェクトの中身を確認することができますが、範囲を指定しないと5559個全てが表示されますので留意してください。
## <<VCorpus>>
## Metadata: corpus specific: 0, document level (indexed): 0
## Content: documents: 2
##
## [[1]]
## <<PlainTextDocument>>
## Metadata: 7
## Content: chars: 49
##
## [[2]]
## <<PlainTextDocument>>
## Metadata: 7
## Content: chars: 23最初のデータには7個のメタデータ(属性)と49文字のテキスト(コンテンツ)が含まれていることがわかります。最初に確認したようにメタデータの大半は空です。テキスト(コンテンツ)を確認するには明示的に文字型を指定すると簡単に参照できます。
## [1] "Hope you are having a good week. Just checking in"## [1] "complimentary 4 STAR Ibiza Holiday or £10,000 cash needs your URGENT collection. 09066364349 NOW from Landline not to lose out! Box434SK38WP150PPM18+"
要素を指定して参照する【テキスト外】
VCorpusオブジェクトはリスト型ですので要素名を指定して参照することも可能です。
## [1] "Hope you are having a good week. Just checking in"## [1] "2019-08-24 06:52:42 GMT"
任意の範囲を参照するにはlaply関数(Base Rにおける層別処理の基本関数群であるapplyシリーズの一つ)を用います。lapply関数は第一引数に指定したオブジェクトに対して、第二引数で指定しhた関数を適用してリスト型で返す関数です。
## $`1`
## [1] "Hope you are having a good week. Just checking in"
##
## $`2`
## [1] "K..give back my thanks."
コーパスの準備ができましたので、ここからがクレンジング処理です。VCorpusオブジェクトはリスト型なので専用の関数を用いてテキストの中身に処理を適用します。適用する各関数の動作はテキストで確認してください。
小文字への変換 【P97】
## [1] "complimentary 4 STAR Ibiza Holiday or £10,000 cash needs your URGENT collection. 09066364349 NOW from Landline not to lose out! Box434SK38WP150PPM18+"## [1] "complimentary 4 star ibiza holiday or £10,000 cash needs your urgent collection. 09066364349 now from landline not to lose out! box434sk38wp150ppm18+"
数字の削除 【P97】
## [1] "complimentary 4 STAR Ibiza Holiday or £10,000 cash needs your URGENT collection. 09066364349 NOW from Landline not to lose out! Box434SK38WP150PPM18+"## [1] "complimentary star ibiza holiday or £, cash needs your urgent collection. now from landline not to lose out! boxskwpppm+"
ストップワードの削除 【P98】
## [1] "complimentary 4 STAR Ibiza Holiday or £10,000 cash needs your URGENT collection. 09066364349 NOW from Landline not to lose out! Box434SK38WP150PPM18+"## [1] "complimentary star ibiza holiday £, cash needs urgent collection. now landline lose ! boxskwpppm+"
記号の削除 【P98-99】
## [1] "complimentary 4 STAR Ibiza Holiday or £10,000 cash needs your URGENT collection. 09066364349 NOW from Landline not to lose out! Box434SK38WP150PPM18+"## [1] "complimentary star ibiza holiday £ cash needs urgent collection now landline lose boxskwpppm"
ステミング 【P99-100】
ステミングにはSnowballCパッケージの関数を用いますので最初に読み込んでおきます。
## [1] "complimentary 4 STAR Ibiza Holiday or £10,000 cash needs your URGENT collection. 09066364349 NOW from Landline not to lose out! Box434SK38WP150PPM18+"## [1] "complimentari star ibiza holiday £ cash need urgent collect now landlin lose boxskwpppm"
連続空白の削除 【P100】
## [1] "complimentary 4 STAR Ibiza Holiday or £10,000 cash needs your URGENT collection. 09066364349 NOW from Landline not to lose out! Box434SK38WP150PPM18+"## [1] "complimentari star ibiza holiday £ cash need urgent collect now landlin lose boxskwpppm"ステミングの時点で余計な空白はすでに削除されているようですが、ここはテキスト通りに処理しています。
以上でクレンジングは終了です。ここか単語単位に分割してドキュメント毎の頻度マトリクスを作成します。
データの準備 - 文書の単語への分割 【P100-101】
クレンジング処理ができましたのでトークン化処理(単語単位への分割)を行います。処理結果はDTM(Document-Term Matrix)と呼ばれる行列形式になります。
## <<DocumentTermMatrix (documents: 5559, terms: 6542)>>
## Non-/sparse entries: 42112/36324866
## Sparsity : 100%
## Maximal term length: 40
## Weighting : term frequency (tf)テキストとは若干値が異なりますが、データ自体やパッケージのバージョンが異なるなどの差異がありますので、あまり気にしないでください。
結果の読み方は、「\(5,559\)」のドキュメント(インスタンス)と「\(6,542\)」の単語(フィーチャー)からなり、最も長い単語が\(40\)文字で、セルの値(度数, term frequency)がゼロでない(Non-sparse)セルが「\(42,112\)」個、残る「\(36,324,866\)」個のセルの値はゼロです。このような行列は疎行列(Sparse Matrix)と呼ばれます。「Sparsity(希薄性)」は、\(99.8842026\%\)で、小数点以下を表示しないために\(100\%\)と表示されています。
この疎行列がナイーブベイズの処理に必要な頻度表を作成するためのベースとなります。
参考までに長いタームのトップ10は以下のようなものです。
data.frame(term = sms_dtm$dimnames$Terms, stringsAsFactors = FALSE) %>%
dplyr::rowwise() %>%
dplyr::mutate(length = nchar(term)) %>%
dplyr::arrange(desc(length)) %>%
head(10)
DTMの実態 【テキスト外】
Document-Term Matrixオブジェクト(sms_dtm)の実態は以下のようなドキュメント(番号)と単語(Term)のマトリクス型データ(頻度表)です。tm::inspect関数を用いると確認することができます。
## <<DocumentTermMatrix (documents: 5559, terms: 6542)>>
## Non-/sparse entries: 42112/36324866
## Sparsity : 100%
## Maximal term length: 40
## Weighting : term frequency (tf)
## Sample :
## Terms
## Docs call can come day free get just know now will
## 1814 1 0 0 0 0 0 0 0 0 0
## 2046 0 0 0 0 0 0 0 1 0 0
## 295 0 0 0 0 1 0 0 0 0 0
## 2993 0 1 0 1 0 0 0 0 0 0
## 313 0 0 1 2 0 1 0 0 0 11
## 3201 0 0 0 0 1 0 0 0 0 0
## 3522 0 0 0 0 0 0 0 0 0 0
## 399 0 0 0 0 0 0 0 0 0 0
## 5068 0 0 0 6 0 0 0 0 0 0
## 5279 0 3 0 0 1 1 0 0 0 0
例えば、クレンジング後の313番目の文書には“will”という単語が11回出てきていることがわかります。クレンジング前の313番目の文書と比べてみましょう。
| x |
|---|
| For me the love should start with attraction.i should feel that I need her every time around me.she should be the first thing which comes in my thoughts.I would start the day and end it with her.she should be there every time I dream.love will be then when my every breath has her name.my life should happen around her.my life will be named to her.I would cry for her.will give all my happiness and take all her sorrows.I will be ready to fight with anyone for her.I will be in love when I will be doing the craziest things for her.love will be when I don’t have to proove anyone that my girl is the most beautiful lady on the whole planet.I will always be singing praises for her.love will be when I start up making chicken curry and end up makiing sambar.life will be the most beautiful then.will get every morning and thank god for the day because she is with me.I would like to say a lot..will tell later.. |
For me the love should start with attraction.i should feel that I need her every time around me.she should be the first thing which comes in my thoughts.I would start the day and end it with her.she should be there every time I dream.love will be then when my every breath has her name.my life should happen around her.my life will be named to her.I would cry for her.will give all my happiness and take all her sorrows.I will be ready to fight with anyone for her.I will be in love when I will be doing the craziest things for her.love will be when I don’t have to proove anyone that my girl is the most beautiful lady on the whole planet.I will always be singing praises for her.love will be when I start up making chicken curry and end up makiing sambar.life will be the most beautiful then.will get every morning and thank god for the day because she is with me.I would like to say a lot..will tell later..
閑話休題。このDTMをスパムと非スパム(ハム)にまとめたものが【P85】にある頻度表です。そこから【表4-3】にあるような尤度表を作成することが可能になります。
ちなみに、DTMを転置させたTermDocumentMatrix(TDM)も作成可能です。
## <<TermDocumentMatrix (terms: 6542, documents: 5559)>>
## Non-/sparse entries: 42112/36324866
## Sparsity : 100%
## Maximal term length: 40
## Weighting : term frequency (tf)
## Sample :
## Docs
## Terms 1814 2046 295 2993 313 3201 3522 399 5068 5279
## call 1 0 0 0 0 0 0 0 0 0
## can 0 0 0 1 0 0 0 0 0 3
## come 0 0 0 0 1 0 0 0 0 0
## day 0 0 0 1 2 0 0 0 6 0
## free 0 0 1 0 0 1 0 0 0 1
## get 0 0 0 0 1 0 0 0 0 1
## just 0 0 0 0 0 0 0 0 0 0
## know 0 1 0 0 0 0 0 0 0 0
## now 0 0 0 0 0 0 0 0 0 0
## will 0 0 0 0 11 0 0 0 0 0
処理ステップについて 【テキスト外】
tm::tm_map関数による処理はtmパッケージを用いて作成したVCorpusオブジェクトにしか適用できないため汎用性はありません(汎化性能が低い)。また、VCorpusオブジェクトはリスト型であるため処理にも相応の時間を必要とします。加えて、テキストの処理ではVCorpusオブジェクトの属性情報は一切利用していません。そうなるとVCorpusオブジェクトで処理する意味はどこにあるのでしょうか?
日本語を処理することを考えるとデータフレームの状態で処理できるtidyverseパッケージによるクレンジング処理の方が汎用性・応用性が高いと考えます。tidyverseパッケージを用いてクレンジング処理をするメリットは
- 処理結果が分かりやすい
- データフレームは表形式で表示できるのでデータを俯瞰しやすい
- 表示に便利なパッケージがそろっている(
DTパッケージなど)
- 処理が汎用的である(汎化性能が高い)
- 日本語特有の変換処理も簡単に対応できる
- ベクトル処理なので処理が高速
- 単純に比較してみたら約10倍の差
などがあげられます。基本的な手順はテキストと同じですが、コーパス化する前にクレンジング処理を行う点が異なります。参考までにデータフレームでクレンジング処理を行う際の手順を記載しておきます。ご興味のある方はご自身で試してみてください。
| Step | Processing | Input Type | Output Type | Package |
|---|---|---|---|---|
| 1 | データの収集 | CSV | ||
| 2 | データの研究と準備 | |||
| -1 | データの読み込みと確認 | CSV | Data Frame | (Base R) |
| -2 | データ型の変換 | Data Frame | Data Frame | (Base R) |
| -4 | クレンジング(小文字化) | Data Frame | Data Frame | tidyverse |
| -5 | クレンジング(数字の削除) | Data Frame | Data Frame | tidyverse |
| -6 | クレンジング(Stopwordの削除) | Data Frame | Data Frame | tidyverse, tm |
| -7 | クレンジング(記号の削除) | Data Frame | Data Frame | tidyverse |
| -8 | クレンジング(ステミング) | Data Frame | Dara Frame | tidyverse, SnowballC |
| -9 | クレンジング(空白の削除) | Data Frame | Data Frame | tidyverse |
| -3 | コーパス化 | Data Frame | List | tm |
| -10 | 単語への分割(トークン化) | List | Matrix | tm |
| -11 | 訓練・テストデータへ分割 | Matrix | Matrix | (Base R) |
| -12 | ラベルデータの作成 | Data Frame | Vector | (Base R) |
| -13 | 頻出度の低いトークンの削除 | Matrix | Matrix | tm |
| -14 | カテゴリカルデータへ変換 | Matrix | Matrix | (Base R) |
| 3 | データによるモデルの訓練 | Matrix, Vector | List | e1071 |
| 4 | モデルの性能評価 | |||
| -1 | 判定(予測)の実行 | List, Matrix | Vector | (Base R) |
| -2 | 判定(予測)結果の評価 | Vector | List | gmodels |
更にtidytextパッケージを用いるとコーパス化することなくデータフレームのみで処理を完結させることが可能になります。
処理ステップによる差について 【P102】
テキストでは二つの処理ステップによる差について記載しておりテキストクレンジングの原則には「操作の順序が意味をもつ」としています。しかし、単に順序が意味をもつのではなく分析の目的に見合ったデータをどのように絞り込むか(目的はなにか)がポイントであり、そのために提供されている手段(関数)がどのようになっているかを理解しておくことがポイントだと考えます。
今回の処理順には以下の背景があります。
- 最初に小文字化するのはストップワードの定義が小文字であるため
- 記号を削除する前にストップワードを削除するのはストップワードに記号が含まれるため
- 数字はスパムであろとうなかろうと含まれているのでスパムの特徴にはならない(なりにくい)ため
- 特定の電話番号や金額などはスパムの特徴になる可能性はある
- ステミングはトークンを抽象化するため
このように対象データを観察して特徴を把握しておくことが重要です。
データの準備 - 訓練、テストデータセットの作成 【P103】
DTMが作成できましたので、DTMの内\(75\%(4169)\)をトレーニング用、残りの\(25\%(1390)\)をテスト用データとして分割します。対象データがマトリクス型なので素直にテキスト通りの処理を行います。
DTMにはラベル要素が含まれていませんので、大元のデータフレームからラベルを作成しておきます。
念の為にトレーニング用、テスト用の各データに含まれるスパムの比率を確認しておきます。
## .
## ham spam
## 0.8647158 0.1352842## .
## ham spam
## 0.8683453 0.1316547トレーニング用データもテスト用データもほぼ同じ比率でスパムが含まれていることがわかります。
テキストデータの可視化 - ワードクラウド 【P103−104】
ワードクラウドはおまけで、ナイーブベイズの処理には必要ありません。SMSのメッセージにはどのようなトークン(単語)が多く含まれているのかを確認するために可視化してみます。このような可視化にはワードクラウドと呼ばれる可視化手法が向いています。

SMSメッセージ全体の傾向がわかりましたので、スパムと非スパムでの傾向の違いが分かるように可視化してみます。

データの準備 - 頻出語のためのインジケータフィーチャーの作成 【P107】
最後にナイーブベイズ分類器を訓練するためのデータを作成します。出現頻度が低いトークン(単語)は訓練に用いてもあまり効果がないと考えられますので、トレーニング用のDTMにおいて出現頻度が5未満の単語を削除して頻出語リスト(ベクトルデータ)を作成します。tm::findFreqTerms関数は与えられたDTMから最低頻度(lowfreq)以上、最高頻度(highfreq)以下の出現頻度の単語を抜き出します。
sms_freq_words <- sms_dtm_train %>%
tm::findFreqTerms(lowfreq = 5, highfreq = Inf)
str(sms_freq_words)## chr [1:1137] "£wk" "abiola" "abl" "abt" "accept" "access" "account" ...
実行結果は省略しますがsms_freq_wordsはベクトル型のデータで1137個のトークン(単語)が含まれています。この結果を用いてトレーニング用、テスト用DTMから頻出語が含まれているデータのみを抜き出します。
## <<DocumentTermMatrix (documents: 4169, terms: 1137)>>
## Non-/sparse entries: 24942/4715211
## Sparsity : 99%
## Maximal term length: 19
## Weighting : term frequency (tf)
## Sample :
## Terms
## Docs call can come free get just know like now will
## 1814 1 0 0 0 0 0 0 0 0 0
## 2046 0 0 0 0 0 0 1 1 0 0
## 295 0 0 0 1 0 0 0 1 0 0
## 2993 0 1 0 0 0 0 0 0 0 0
## 313 0 0 1 0 1 0 0 1 0 11
## 3201 0 0 0 1 0 0 0 1 0 0
## 3507 1 0 0 0 0 2 0 0 0 1
## 3522 0 0 0 0 0 0 0 0 0 0
## 399 0 0 0 0 0 0 0 0 0 0
## 808 0 0 0 0 0 0 1 0 0 0## <<DocumentTermMatrix (documents: 1390, terms: 1137)>>
## Non-/sparse entries: 7981/1572449
## Sparsity : 99%
## Maximal term length: 19
## Weighting : term frequency (tf)
## Sample :
## Terms
## Docs call can come day get just know love now will
## 4243 1 0 0 1 0 0 1 0 0 0
## 4413 1 0 0 0 0 0 0 0 0 0
## 4493 0 1 1 0 0 0 1 0 0 0
## 4515 0 1 0 0 3 0 0 0 0 0
## 4649 1 0 0 0 0 0 0 0 0 0
## 4830 0 2 0 0 1 0 0 0 0 1
## 5068 0 0 0 6 0 0 0 0 0 0
## 5279 0 3 0 0 1 0 0 0 0 0
## 5359 1 2 1 0 1 1 0 0 1 0
## 5488 1 1 0 0 0 1 1 0 0 0次にトレーニング、テスト用データを二値化します。
convert_counts <- function(x) {
x <- ifelse(x > 0, "Yes", "No")
}
sms_train <- apply(sms_dtm_freq_train, MARGIN = 2, convert_counts)
sms_test <- apply(sms_dtm_freq_test, MARGIN = 2, convert_counts)## <<DocumentTermMatrix (documents: 4169, terms: 1137)>>
## Non-/sparse entries: 24942/4715211
## Sparsity : 99%
## Maximal term length: 19
## Weighting : term frequency (tf)
## Sample :
## Terms
## Docs call can come free get just know like now will
## 1814 1 0 0 0 0 0 0 0 0 0
## 2046 0 0 0 0 0 0 1 1 0 0
## 295 0 0 0 1 0 0 0 1 0 0
## 2993 0 1 0 0 0 0 0 0 0 0
## 313 0 0 1 0 1 0 0 1 0 11
## 3201 0 0 0 1 0 0 0 1 0 0
## 3507 1 0 0 0 0 2 0 0 0 1
## 3522 0 0 0 0 0 0 0 0 0 0
## 399 0 0 0 0 0 0 0 0 0 0
## 808 0 0 0 0 0 0 1 0 0 0sms_train[c("1814", "2046", "295", "2993", "313", "3201", "3507", "3522",
"399", "808"),
c("call", "can", "come", "day", "free", "get", "just", "like",
"now", "will")]## Terms
## Docs call can come day free get just like now will
## 1814 "Yes" "No" "No" "No" "No" "No" "No" "No" "No" "No"
## 2046 "No" "No" "No" "No" "No" "No" "No" "Yes" "No" "No"
## 295 "No" "No" "No" "No" "Yes" "No" "No" "Yes" "No" "No"
## 2993 "No" "Yes" "No" "Yes" "No" "No" "No" "No" "No" "No"
## 313 "No" "No" "Yes" "Yes" "No" "Yes" "No" "Yes" "No" "Yes"
## 3201 "No" "No" "No" "No" "Yes" "No" "No" "Yes" "No" "No"
## 3507 "Yes" "No" "No" "No" "No" "No" "Yes" "No" "No" "Yes"
## 3522 "No" "No" "No" "No" "No" "No" "No" "No" "No" "No"
## 399 "No" "No" "No" "No" "No" "No" "No" "No" "No" "No"
## 808 "No" "No" "No" "No" "No" "No" "No" "No" "No" "No"## <<DocumentTermMatrix (documents: 1390, terms: 1137)>>
## Non-/sparse entries: 7981/1572449
## Sparsity : 99%
## Maximal term length: 19
## Weighting : term frequency (tf)
## Sample :
## Terms
## Docs call can come day get just know love now will
## 4243 1 0 0 1 0 0 1 0 0 0
## 4413 1 0 0 0 0 0 0 0 0 0
## 4493 0 1 1 0 0 0 1 0 0 0
## 4515 0 1 0 0 3 0 0 0 0 0
## 4649 1 0 0 0 0 0 0 0 0 0
## 4830 0 2 0 0 1 0 0 0 0 1
## 5068 0 0 0 6 0 0 0 0 0 0
## 5279 0 3 0 0 1 0 0 0 0 0
## 5359 1 2 1 0 1 1 0 0 1 0
## 5488 1 1 0 0 0 1 1 0 0 0sms_test[c("4243", "4413", "4493", "4515", "4649", "4830", "5068", "5090",
"5279", "5359"),
c("call", "can", "come", "day", "free", "get", "just", "like",
"now", "will")]## Terms
## Docs call can come day free get just like now will
## 4243 "Yes" "No" "No" "Yes" "No" "No" "No" "No" "No" "No"
## 4413 "Yes" "No" "No" "No" "No" "No" "No" "No" "No" "No"
## 4493 "No" "Yes" "Yes" "No" "No" "No" "No" "No" "No" "No"
## 4515 "No" "Yes" "No" "No" "No" "Yes" "No" "No" "No" "No"
## 4649 "Yes" "No" "No" "No" "No" "No" "No" "No" "No" "No"
## 4830 "No" "Yes" "No" "No" "No" "Yes" "No" "No" "No" "Yes"
## 5068 "No" "No" "No" "Yes" "No" "No" "No" "No" "No" "No"
## 5090 "Yes" "No" "No" "No" "No" "No" "No" "Yes" "No" "No"
## 5279 "No" "Yes" "No" "No" "Yes" "Yes" "No" "No" "No" "No"
## 5359 "Yes" "Yes" "Yes" "No" "No" "Yes" "Yes" "No" "Yes" "No"
ステップ3 - データによるモデルの訓練 【P108】
ここからがData Science Workflowにおける“Model”プロセスに該当するモデリング処理に該当します。Rにおけるナイーブベイズのモデリングは非常に単純で以下の関数を実行すれば完了します。計算結果は膨大なので表示は省略します。
ナイーブベイズを行うために必要なデータ【テキスト外】
様々な処理をしてきたので分かりにくいですが、ナイーブベイズで学習を行うために必要なデータは以下の二つのみです。それ以外のデータは全てこれらのデータを作成するためのデータです。
- カテゴライズされたDTM(マトリクス型変数)
- 上記に対するラベルデータ(ベクトル型変数(atomic vector))
sms_train[c("1814", "2046", "295", "2993", "313", "3201", "3507", "3522",
"399", "808"),
c("call", "can", "come", "day", "free", "get", "just", "like",
"now", "will")]## Terms
## Docs call can come day free get just like now will
## 1814 "Yes" "No" "No" "No" "No" "No" "No" "No" "No" "No"
## 2046 "No" "No" "No" "No" "No" "No" "No" "Yes" "No" "No"
## 295 "No" "No" "No" "No" "Yes" "No" "No" "Yes" "No" "No"
## 2993 "No" "Yes" "No" "Yes" "No" "No" "No" "No" "No" "No"
## 313 "No" "No" "Yes" "Yes" "No" "Yes" "No" "Yes" "No" "Yes"
## 3201 "No" "No" "No" "No" "Yes" "No" "No" "Yes" "No" "No"
## 3507 "Yes" "No" "No" "No" "No" "No" "Yes" "No" "No" "Yes"
## 3522 "No" "No" "No" "No" "No" "No" "No" "No" "No" "No"
## 399 "No" "No" "No" "No" "No" "No" "No" "No" "No" "No"
## 808 "No" "No" "No" "No" "No" "No" "No" "No" "No" "No"## [1] ham ham ham ham ham ham ham ham ham ham
## Levels: ham spam
ステップ4 - モデルの性能評価 【P109】
モデルが完成しましたのでpredict関数を用いて予測(分類)を行います。予測(分類)結果はベクトル変数になります。
## [1] ham ham ham ham spam ham ham ham ham spam ham ham ham
## [14] spam spam ham ham ham ham ham ham ham ham ham ham ham
## [27] ham ham ham ham ham ham ham ham spam ham ham ham ham
## [40] spam ham ham ham ham ham ham ham ham ham spam ham ham
## [53] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [66] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [79] ham ham spam ham ham ham ham ham ham ham ham ham ham
## [92] ham ham ham ham ham ham spam ham ham ham ham ham ham
## [105] ham ham ham ham ham spam spam ham ham ham ham ham ham
## [118] ham ham ham ham ham ham ham ham spam ham ham ham ham
## [131] ham ham spam ham ham ham ham ham ham ham ham ham ham
## [144] ham ham ham spam ham ham ham ham ham spam ham spam ham
## [157] ham ham spam ham ham ham ham ham spam ham ham ham spam
## [170] ham ham ham ham ham ham ham ham ham spam ham ham ham
## [183] ham ham ham ham spam ham ham ham spam ham ham ham ham
## [196] ham ham ham ham spam spam ham ham ham ham ham ham ham
## [209] ham spam ham ham ham ham ham ham spam ham ham ham ham
## [222] ham ham ham ham ham ham ham ham ham ham ham ham spam
## [235] ham ham ham ham spam ham ham ham ham ham ham ham ham
## [248] ham ham spam ham ham ham ham ham ham ham ham ham ham
## [261] ham ham ham ham ham ham ham ham ham spam ham ham ham
## [274] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [287] ham ham ham ham ham spam ham ham ham ham ham spam ham
## [300] ham ham ham ham ham ham ham ham spam ham ham ham spam
## [313] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [326] ham ham spam ham ham ham ham ham ham ham ham spam ham
## [339] ham ham ham ham ham ham ham ham spam spam ham ham ham
## [352] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [365] ham ham ham spam ham ham ham ham ham ham ham ham ham
## [378] ham spam ham ham ham ham spam ham spam ham ham ham ham
## [391] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [404] ham ham spam ham ham spam ham ham ham spam spam ham ham
## [417] ham ham ham ham spam ham ham ham ham ham ham ham ham
## [430] ham ham ham ham ham spam ham spam ham ham ham ham ham
## [443] ham ham ham ham ham spam ham ham ham spam ham ham ham
## [456] ham ham ham ham ham ham ham ham spam ham ham ham ham
## [469] ham ham ham ham ham ham ham ham ham ham spam ham ham
## [482] ham spam ham ham ham ham ham ham spam ham ham ham ham
## [495] ham ham spam ham ham spam spam spam ham ham ham ham ham
## [508] ham spam ham ham ham ham spam ham ham ham ham ham ham
## [521] ham ham ham spam ham ham ham ham ham ham ham ham ham
## [534] ham ham spam ham spam ham ham ham ham ham ham spam ham
## [547] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [560] ham ham ham ham spam ham ham ham ham ham ham ham ham
## [573] ham ham ham ham spam ham ham ham ham ham ham ham ham
## [586] ham ham ham ham spam ham ham ham ham ham ham ham ham
## [599] ham ham ham ham ham ham ham ham ham spam ham spam ham
## [612] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [625] spam ham ham ham spam ham ham ham ham ham ham ham ham
## [638] ham ham spam ham ham ham ham ham ham ham ham ham spam
## [651] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [664] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [677] spam ham ham ham ham ham ham ham ham spam spam ham ham
## [690] spam ham ham spam ham ham ham ham ham ham ham ham ham
## [703] ham ham ham ham ham spam ham ham ham ham ham ham ham
## [716] ham spam ham ham ham ham ham ham ham ham ham ham ham
## [729] ham ham spam ham spam ham ham spam ham ham ham ham spam
## [742] ham spam ham ham ham ham ham spam ham spam ham ham ham
## [755] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [768] ham ham spam ham ham ham ham ham ham ham ham ham ham
## [781] spam ham ham ham ham ham ham ham ham ham ham ham ham
## [794] ham ham ham ham ham ham ham ham spam ham ham ham ham
## [807] ham ham ham ham ham ham ham spam ham ham spam ham spam
## [820] ham ham ham ham spam ham spam ham spam ham ham ham spam
## [833] ham ham ham ham spam ham ham ham ham ham ham ham ham
## [846] ham ham ham ham ham ham ham ham ham ham ham ham spam
## [859] ham ham spam ham ham ham ham ham ham ham ham ham ham
## [872] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [885] ham ham ham ham ham ham ham ham ham ham ham spam spam
## [898] ham ham spam ham ham ham ham ham ham ham ham spam ham
## [911] ham ham ham spam ham ham ham ham ham ham ham ham ham
## [924] ham ham ham ham ham ham ham spam ham ham ham ham ham
## [937] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [950] ham ham ham ham ham ham spam ham ham ham ham ham ham
## [963] ham ham ham ham spam ham ham ham ham ham ham ham ham
## [976] ham ham ham ham spam ham ham ham ham ham ham ham ham
## [989] ham ham ham ham ham spam ham ham ham ham ham spam ham
## [1002] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [1015] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [1028] ham ham ham ham ham spam ham spam ham ham ham ham spam
## [1041] ham spam ham ham ham ham ham ham ham ham ham ham ham
## [1054] ham spam ham ham ham ham ham ham ham ham ham ham ham
## [1067] ham ham ham ham ham ham ham ham ham spam ham ham ham
## [1080] ham ham ham ham ham ham ham ham ham spam ham ham ham
## [1093] ham ham ham ham ham ham ham ham spam ham ham ham ham
## [1106] ham ham ham ham ham ham spam ham ham ham ham ham ham
## [1119] ham ham ham ham ham ham ham spam ham ham ham ham spam
## [1132] ham ham ham spam ham ham ham ham ham ham ham ham ham
## [1145] ham ham ham ham ham ham ham ham spam ham ham ham ham
## [1158] ham ham ham spam ham ham ham ham ham ham ham ham ham
## [1171] ham ham ham spam spam ham ham ham ham ham spam ham ham
## [1184] ham ham ham ham ham ham ham ham ham spam ham spam ham
## [1197] ham ham spam ham ham ham ham ham ham ham ham spam ham
## [1210] ham ham ham ham spam ham ham spam ham ham spam ham ham
## [1223] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [1236] ham ham spam ham ham ham ham spam ham ham ham ham ham
## [1249] ham ham spam ham ham ham ham ham ham spam ham ham ham
## [1262] ham ham ham ham ham ham ham ham spam ham ham ham spam
## [1275] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [1288] ham ham ham ham ham ham ham ham ham ham ham ham ham
## [1301] ham spam ham ham ham spam ham ham ham ham spam ham ham
## [1314] ham ham ham ham ham ham spam ham ham ham spam spam ham
## [1327] ham spam ham ham ham ham ham ham ham ham ham ham ham
## [1340] spam ham ham spam ham spam ham ham ham ham ham spam ham
## [1353] spam ham ham ham spam ham ham ham ham ham ham spam ham
## [1366] ham ham ham ham spam ham ham ham ham ham ham ham ham
## [1379] ham ham ham ham spam ham ham ham ham spam ham ham
## Levels: ham spamgmodels::CrossTable(sms_test_pred, sms_test_labels,
prop.chisq = FALSE, prop.t = FALSE, prop.r = FALSE,
dnn = c('predicted', 'actual'))##
##
## Cell Contents
## |-------------------------|
## | N |
## | N / Col Total |
## |-------------------------|
##
##
## Total Observations in Table: 1390
##
##
## | actual
## predicted | ham | spam | Row Total |
## -------------|-----------|-----------|-----------|
## ham | 1201 | 30 | 1231 |
## | 0.995 | 0.164 | |
## -------------|-----------|-----------|-----------|
## spam | 6 | 153 | 159 |
## | 0.005 | 0.836 | |
## -------------|-----------|-----------|-----------|
## Column Total | 1207 | 183 | 1390 |
## | 0.868 | 0.132 | |
## -------------|-----------|-----------|-----------|
##
##
ステップ5 - モデル性能の改善 【P110-111】
更にラプラス推定量を変えてみると偽陰性(FN)は減り、擬陽性(FP)が増えるというテキストとは異なる結果になりました。偽陰性が減るのはテキストにあるように好ましい傾向だと考えられます。
e1071::naiveBayes(sms_train, sms_train_labels, laplace = 1) %>%
predict(sms_test) %>%
gmodels::CrossTable(sms_test_labels,
prop.chisq = FALSE, prop.t = FALSE, prop.r = FALSE,
dnn = c('predicted', 'actual'))##
##
## Cell Contents
## |-------------------------|
## | N |
## | N / Col Total |
## |-------------------------|
##
##
## Total Observations in Table: 1390
##
##
## | actual
## predicted | ham | spam | Row Total |
## -------------|-----------|-----------|-----------|
## ham | 1202 | 28 | 1230 |
## | 0.996 | 0.153 | |
## -------------|-----------|-----------|-----------|
## spam | 5 | 155 | 160 |
## | 0.004 | 0.847 | |
## -------------|-----------|-----------|-----------|
## Column Total | 1207 | 183 | 1390 |
## | 0.868 | 0.132 | |
## -------------|-----------|-----------|-----------|
##
## 更にラプラス推定量を変えてみると最初の結果より悪化していますので、これ以上、変えない方がいいのかも知れません。
e1071::naiveBayes(sms_train, sms_train_labels, laplace = 2) %>%
predict(sms_test) %>%
gmodels::CrossTable(sms_test_labels,
prop.chisq = FALSE, prop.t = FALSE, prop.r = FALSE,
dnn = c('predicted', 'actual'))##
##
## Cell Contents
## |-------------------------|
## | N |
## | N / Col Total |
## |-------------------------|
##
##
## Total Observations in Table: 1390
##
##
## | actual
## predicted | ham | spam | Row Total |
## -------------|-----------|-----------|-----------|
## ham | 1204 | 34 | 1238 |
## | 0.998 | 0.186 | |
## -------------|-----------|-----------|-----------|
## spam | 3 | 149 | 152 |
## | 0.002 | 0.814 | |
## -------------|-----------|-----------|-----------|
## Column Total | 1207 | 183 | 1390 |
## | 0.868 | 0.132 | |
## -------------|-----------|-----------|-----------|
##
##
交差検証 【テキスト外】
ナイーブベイズの交差検証はcaretパッケージのcaret::train関数で実行できますが、ナイーブベイズのモデリングに使えるパッケージは下表にあるパッケージのみです。なお、計算には時間がかかりますのでパラレル処理を利用するなどしてください。
| method | modeling package | parameters |
|---|---|---|
| naive_bayes | naivebayes | laplace (Laplace Correction), usekernel (Distribution Type), adjust (Bandwidth Adjustment) |
| nb | klaR | fL (Laplace Correction), usekernel (Distribution Type), adjust (Bandwidth Adjustment) |
cl <- parallel::makePSOCKcluster(4L)
doParallel::registerDoParallel(cl)
caret::train(x = sms_train, y = sms_train_labels, method = "nb",
tuneGrid = expand.grid(fL = c(0:5), usekernel = FALSE, adjust = 1),
trControl = caret::trainControl(method = "cv"))## Naive Bayes
##
## 4169 samples
## 1137 predictors
## 2 classes: 'ham', 'spam'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold)
## Summary of sample sizes: 3752, 3752, 3752, 3753, 3752, 3751, ...
## Resampling results across tuning parameters:
##
## fL Accuracy Kappa
## 0 0.9791384 0.906909136
## 1 0.9717031 0.883522053
## 2 0.9114979 0.700553444
## 3 0.7080813 0.344592793
## 4 0.2911866 0.056382450
## 5 0.1412808 0.001892734
##
## Tuning parameter 'usekernel' was held constant at a value of FALSE
##
## Tuning parameter 'adjust' was held constant at a value of 1
## Accuracy was used to select the optimal model using the largest value.
## The final values used for the model were fL = 0, usekernel = FALSE
## and adjust = 1.klaR::NaiveBayes(x = sms_train, grouping = sms_train_labels,
fL = 0, usekernel = FALSE, adjust = 1) %>%
predict(sms_test) %>%
.$class %>% # e1071::naiveBayes()関数とは返り値が異なるため
gmodels::CrossTable(sms_test_labels,
prop.chisq = FALSE, prop.t = FALSE, prop.r = FALSE,
dnn = c('predicted', 'actual'))##
##
## Cell Contents
## |-------------------------|
## | N |
## | N / Col Total |
## |-------------------------|
##
##
## Total Observations in Table: 1390
##
##
## | actual
## predicted | ham | spam | Row Total |
## -------------|-----------|-----------|-----------|
## ham | 1201 | 30 | 1231 |
## | 0.995 | 0.164 | |
## -------------|-----------|-----------|-----------|
## spam | 6 | 153 | 159 |
## | 0.005 | 0.836 | |
## -------------|-----------|-----------|-----------|
## Column Total | 1207 | 183 | 1390 |
## | 0.868 | 0.132 | |
## -------------|-----------|-----------|-----------|
##
##
4.3 まとめ 【P111】
ナイーブベイズはベイズの定理に基づくので考え方自体はシンプルですが、尤度と事前確率が事後確率に大きな影響を与えるのでトレーニング用データを慎重に選ぶ必要があります。しかしながら、シンプルな考え方にも関わらず良い感じの分類精度を出してくれることができます。また、ナイーブベイズを用いるためには事前のデータハンドリング(前処理)がポイントになることも学びました。しかしながら、本章では訓練の最適化(交差検証など)について触れていません。これは第11章で触れるからだと思われます。
テキスト分類の使いみちについては今ひとつピンときません。どのような業務で利用できるのでしょうか?
参考資料
ナイーブベイズ関連
- Probabilistic Learning - Classification Using Naive Bayes
- Evaluating Model Performance
- 新はてなブックマークでも使われてるComplement Naive Bayesを解説するよ
- ナイーブベイズを用いたテキスト分類
- ベイズの定理とは?ナイーブベイズを利用した自動FAQシステムの構築
- 機械学習入門者向け Naive Bayes(単純ベイズ)アルゴリズムに触れてみる
- ナイーブベイズ分類器を頑張って丁寧に解説してみる
- 単純ベイズ分類器
- ナイーブベイズを用いたテキスト分類 【Recommend】
- 確率における独立と従属の意味と例
- ナイーブベイズ分類器でTwitterの男女判別!
- Naive Bayes Classifer (Gaussian, Kernel)で分類
- The caret Package
tmパッケージ関連
- tm:言語処理とちょっとだけ嵌る
- Rのtmパッケージメモ
- tmパッケージのメモ
- {tm}パッケージで日本語のPDFからテキストを抽出する
- tmパッケージを使ったサンプル [R言語]
- R_tmパッケージの使い方
テキストマイニング関連
- Rによる自然言語研究環境の整備(PDF)
- Stemming algorithms, Package SnowballC
- Stopwords data, Package SnowballC
- Text Mining with R